Your CEO is about to ask whose team the agents belong to. The question is wrong, and answering it wrong is how People Ops quietly loses the seat at the org-design table.

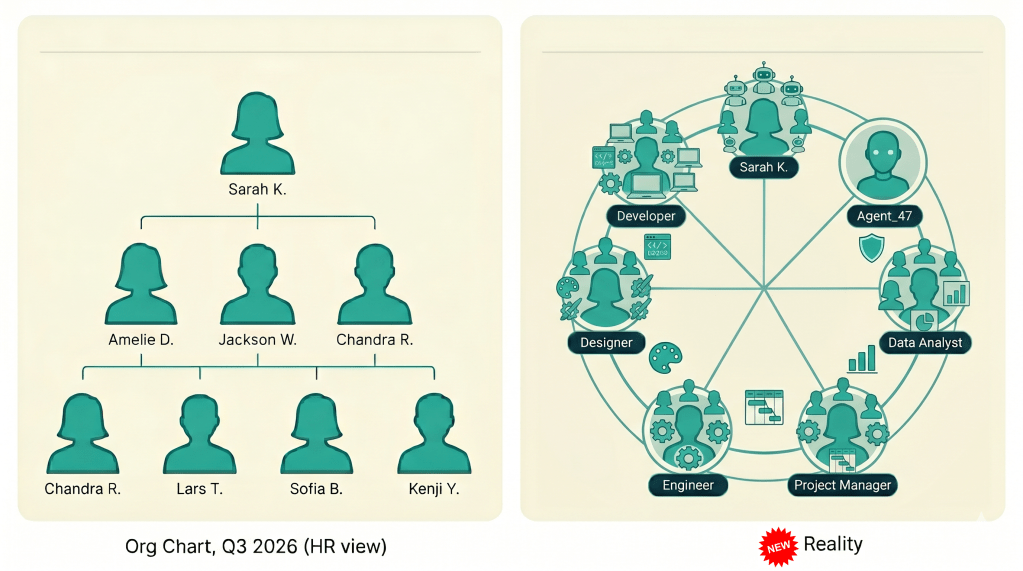
The question came in at 9:14 on a Tuesday. Her CEO leaned in: “We just added agents to the support team. Does HR own them, or does Eng?”
She did not have an answer. Neither did her HRIS, her ladder doc, or her calibration template. A senior IC on her team had quietly started running three coding agents in parallel. The level guide had no row that described any of it.
Most People Ops leaders haven’t had this conversation yet. Their CEO is about to start it. The broader frame is in The H in HR Now Stands for Hybrid. This post is the operational follow-on: how to run performance management when half the team is not human, without repeating the 2024 mistakes.
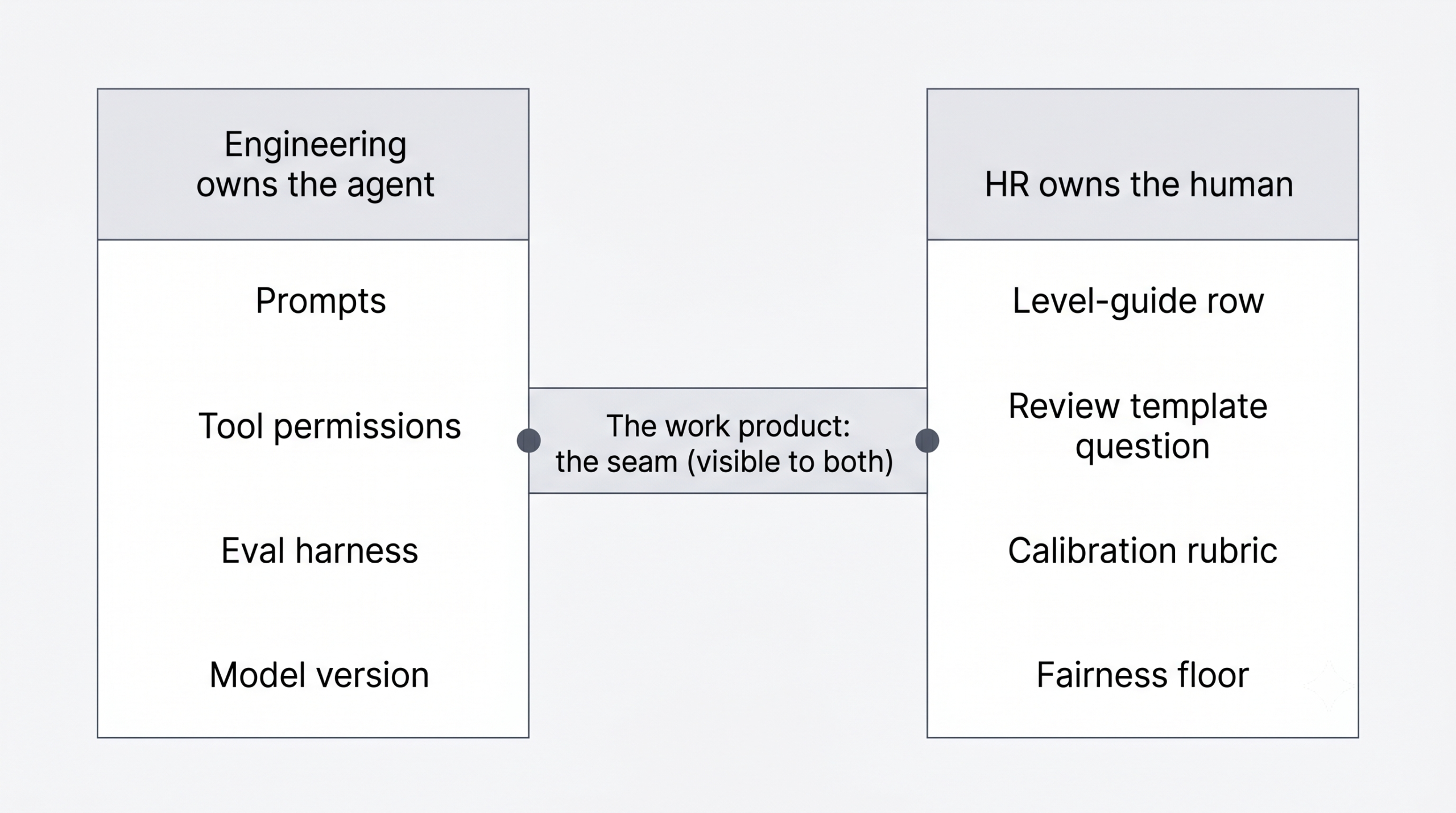
You do not review the AI teammate the way you review a person. You review three things instead: the work the team produced when the agent was in the loop, the humans whose judgment routed that work, and the agent’s prompt, tool permissions, and model version. That last surface is configurable, engineering owns it, and HR co-instruments it.
The agent is not on the ladder. It is not in the comp band. It is not in the calibration cohort.
The agent has a config file, not a career, not yet at least.
What HR owns: the level-guide row for agent-paired work, the review template that captures human judgment, the calibration protocol that doesn’t penalize the IC whose output compounds through agents. Engineering owns the agent. HR owns the human who routes it. The seam is the work product. The failure mode this prevents is attribution collapse: the agent gets credit in the log, the human’s judgment disappears at calibration, your strongest IC quietly leaves.
Do you give performance reviews to AI agents?
No. Performance reviews develop careers, calibrate compensation, and protect due process. An agent has none of those. It has a config file, an eval harness, a tool permission scope, a model version. Engineering manages those. The verb is “evaluate.” A bad outcome feeds back into a prompt diff or model swap inside the same week. Not a 90-day PIP.
The verb HR needs is review the work the team produced with the agent in the loop. Different artifact. That artifact is what this playbook is about.
Who manages AI coworkers?
A note on terminology before the answer. This piece uses “Engineering” as shorthand for whatever team ships and operates the agent in your org. In some companies that team is IT. In others it is Platform, DevOps, or Product. The seam works the same way regardless. Substitute the function name that fits your structure.
Engineering manages the agent’s behavior. Prompts, tools, retries, the eval harness that flags drift. Treat that work like any production service.
HR manages the people who work alongside the agent: the orchestrator IC, the reviewer who approves the agent’s PRs, the support lead who escalates, the manager who calibrates them all. The job is not to give the agent feedback. The job is to make sure the humans next to the agent are evaluated on the right artifact, on a fair cadence, by a cohort that knows compounding output from inflated output.
Eng owns the agent. HR owns the human. The work product is the seam, visible to both.
How does HR change when AI agents join the team?
Three changes, in order of urgency.
- Your level guide needs a row. “Ships features independently” is the IC4 line. You need a parallel: “scopes work, routes it across human and agent collaborators, owns the outcome.” Without that row, you cannot calibrate fairly.
- Your review template needs a question. “Describe one decision you made this cycle to route work to or away from an agent, and what you learned.” That surfaces the judgment that does not appear in commits.
- Your calibration protocol needs a guardrail. If two ICs ship the same volume and one used agents, the cohort needs an explicit rubric for routing and judgment. Otherwise you promote on volume, and the IC who did the harder work walks at the next cycle.
Not on this list: rating the agent, retaining agent outputs in your HRIS, adding the agent as a user in your perf tool. Those were tried in 2024. They failed.
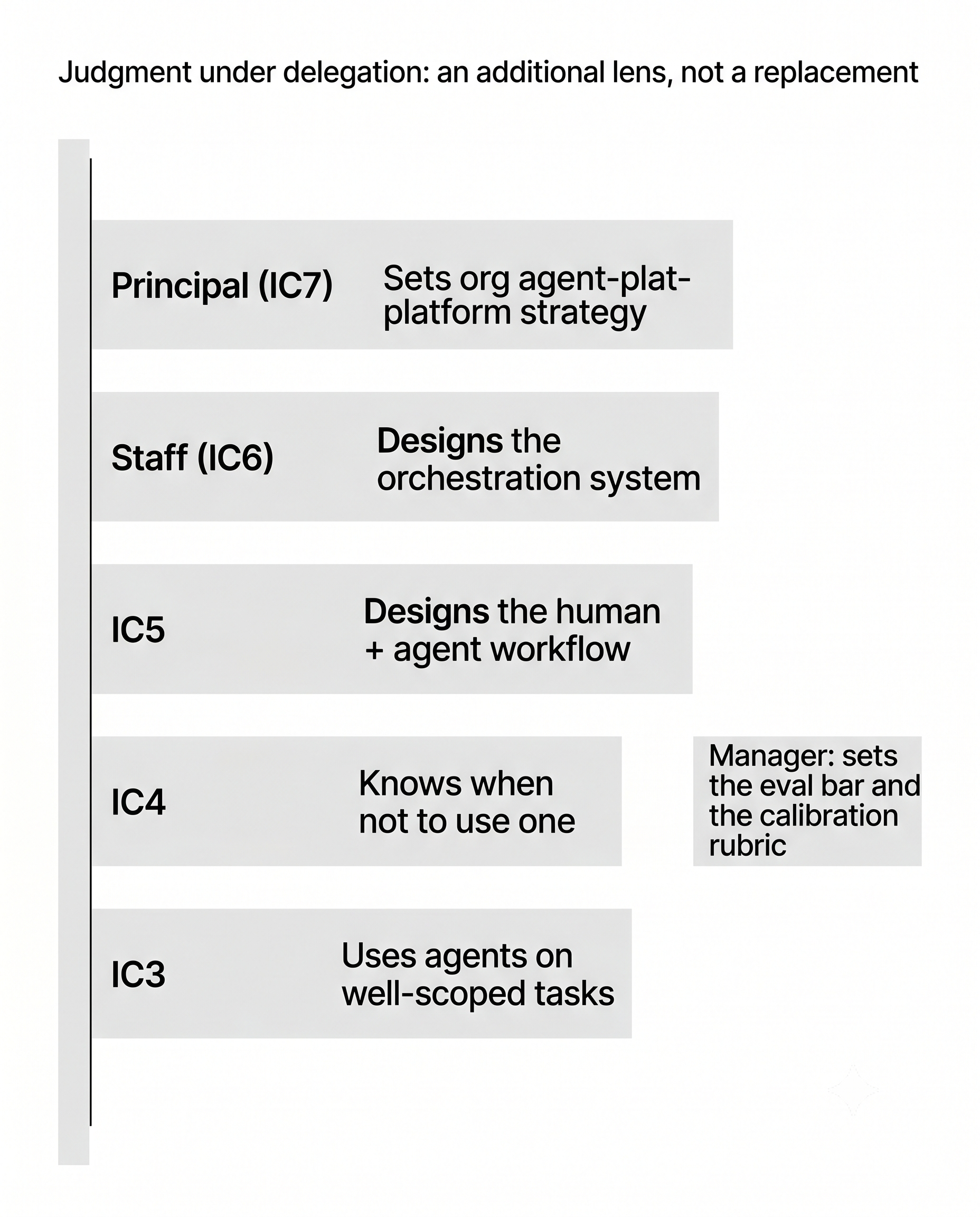
What does the level-guide row look like?
An additional lens, not a replacement for technical depth. An IC4 is an IC4 by the existing ladder; this row tells you whether their delegation work is at level. Engineering template, adapt to any function:
- IC3. Uses agents for well-scoped tasks. Reviews output before merge.
- IC4. Scopes work for agent collaborators. Knows when not to use one. Owns the outcome end to end. Notices failure modes before they cost the team.
- IC5. Designs the human + agent workflow for a squad. Sets the eval signals. Coaches peers on routing.
- IC6 (Staff). Designs the orchestration system the squad uses. Owns the eval harness and drift telemetry. Decides which capabilities to build as agents vs services.
- IC7 (Principal). Sets the org’s agent-platform strategy. Coaches Staff engineers on the trade-offs.
- Manager. Sets the eval bar for the team’s agents and the calibration rubric that prevents promoting on inflated output. Holds the budget seam between agent spend and headcount spend, so the CFO question lands in the right room.
The row is not “uses AI tools.” Every IC uses AI tools by now. The row is judgment under delegation: what to route, what to keep, how to verify.
How do you credit the human in agent-paired work?
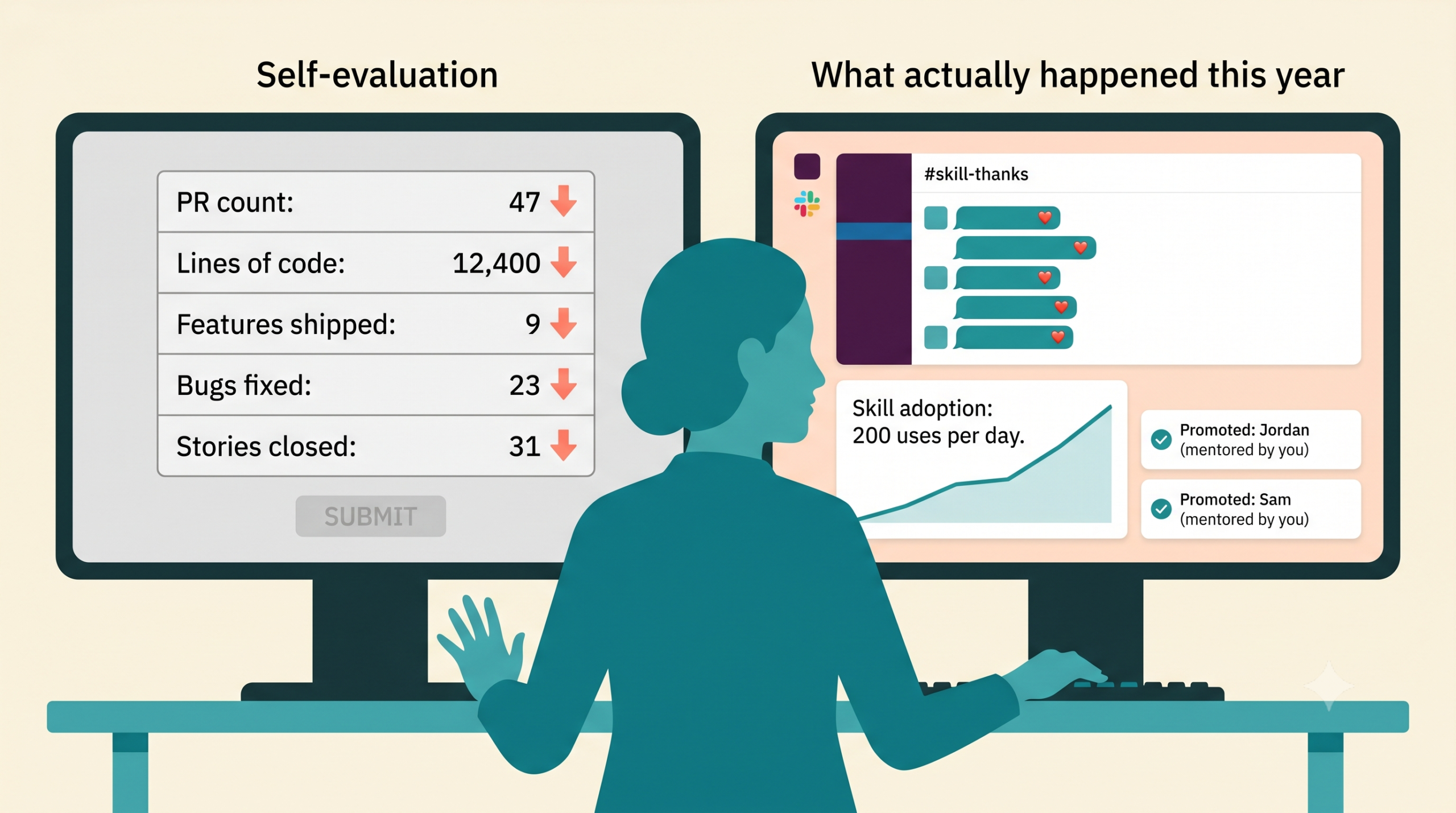
An IC’s commits look smaller because the agent wrote part of them. The judgment got bigger. The system that rates the IC only sees the commits. That is the visibility crisis your senior ICs are quietly experiencing.
Three moves close the gap.
Capture the judgment artifact at the work surface. A two-line note on the PR: “delegated scaffold to agent, kept architecture call, caught regression in review.” Not a form. Searchable at calibration time.
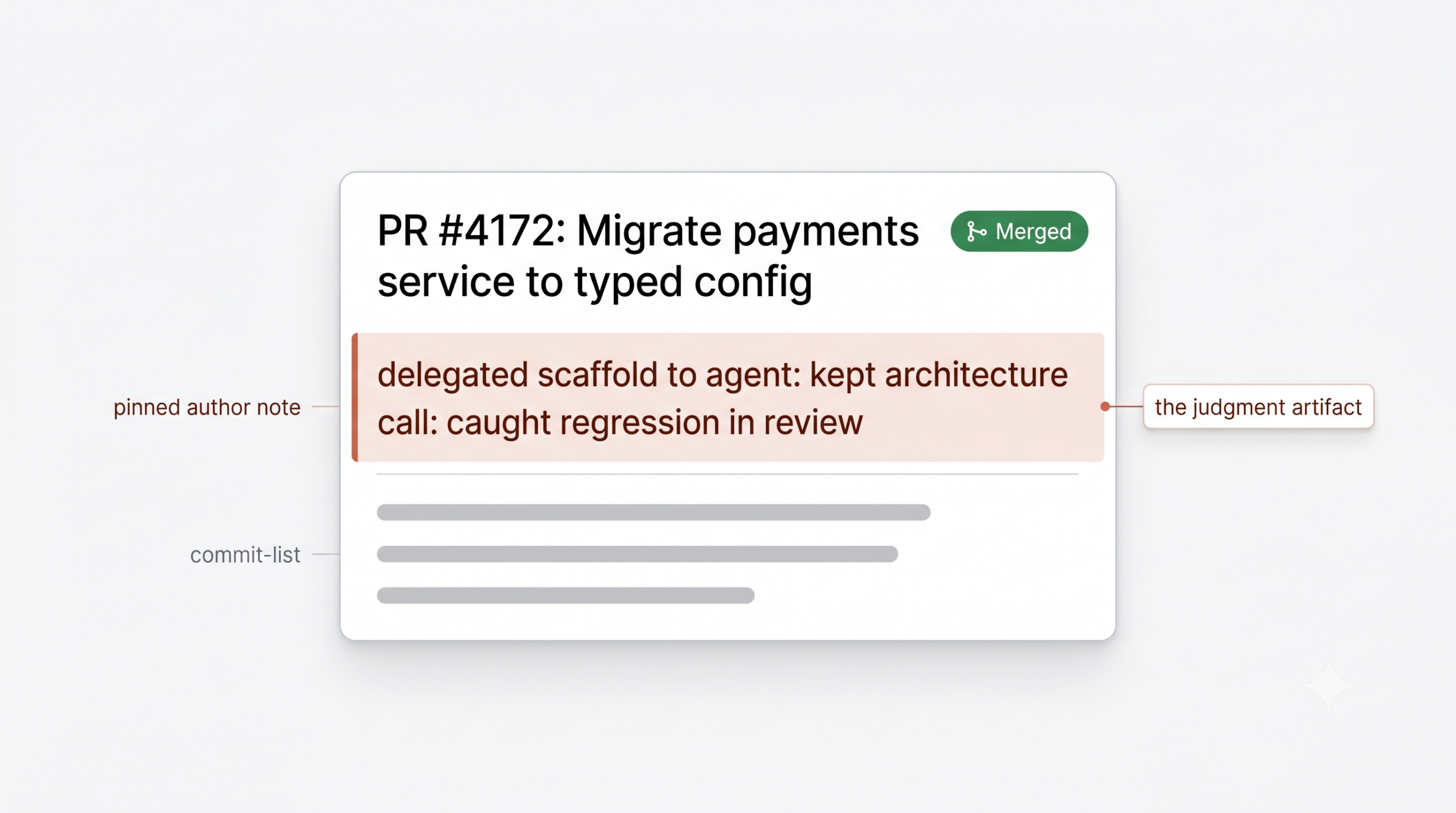
Make feedback follow the work, not the cycle. A teammate who notices a routing call writes a sentence on the PR, not in a quarterly form. A form-based model assumes the reviewer remembers details 90 days later. Agent-paired work moves too fast for that.
Measure feedback quality, not volume. Pulse-response counts tell you nothing about whether the IC is being seen. Specific, dated, decision-level feedback tells you everything.
Your work can speak for you, when the system remembers.
What goes wrong if HR doesn’t update the playbook?
Four failure modes.
- Calibration drift. Two ICs at the same level, one heavy agent user, one not. Without the row, the committee reaches for shipping volume and promotes on output instead of judgment. The IC who did the harder work walks at the next cycle. You can feel this coming and still miss it.
- Attribution collapse. The IC does the work. The commit log says the agent did. The manager writes three sentences from what was logged, one of them wrong about what she actually built. She reads it. She leaves.
- The “digital workers” trap. A vendor or a CHRO frames agents as peers in the org. Legal asks who signs the offer letter. Finance asks who pays them. The category collapses inside a quarter. An HR-tech vendor tried it in August 2024 and the industry rejected the framing within weeks.
- The CFO override. Without an HR playbook, the CFO improvises one. The improvisation is usually “agents reduce the line.” HR loses the seat at the org-design table, and the company under-invests in the judgment that makes agents work.
Calibration drift is silent. The digital workers trap is loud. The CFO override is political. Attribution collapse is the one that costs you your best people.

Comparison: human teammate, AI teammate, AI tool
| Dimension | Human teammate | AI teammate (agent in the loop) | AI tool |
|---|---|---|---|
| Review cadence | Quarterly cycle + continuous feedback | Continuous: per-task eval, weekly drift check | None; product telemetry only |
| Who rates | Manager + peers + self, via calibration | Engineering evaluates the agent; HR evaluates the human routing it | The user clicking it |
| What is rated | Skills, competencies, outcomes, career growth | Output quality, drift, escalation behavior. Not career growth | Feature use, satisfaction |
| Data retention | Per HR data retention policy | Per engineering observability policy | Per product analytics |
The human is evaluated on a career. The agent is evaluated on a job. The perf tool that pretends they are the same artifact will lose the calibration room.
The agent is not the protagonist of the HR story. The human routing it is.
Branco’s structural commitments on what our own agents will and won’t decide live at /agents-trust.
FAQ
Do AI agents get performance reviews?
No. Engineering runs an evaluation loop on the agent. HR reviews the humans who work alongside the agent. Confusing the two is how vendors got into trouble in 2024.
Do AI agents count as headcount?
No. The org chart tracks people with careers, comp, and due process rights. Agents have a config file. The right answer to your CFO: “they are a multiplier on engineering’s budget, not a row in the org chart.”
Who owns AI agents inside the company?
Engineering owns the agent’s behavior. HR owns the people who work with the agent. The seam between them is the work product, visible to both.
How do you stop promoting on volume when agents inflate output?
Add a level-guide row that levels routing and judgment, not shipping count. Capture the judgment artifact at the work surface. Calibrate against the row, not the leaderboard.
How Branco Helps
Branco runs the performance management cycle and the agent orchestration layer on the same data model. Four primitives in the product map directly to the four moves in this playbook.
- Level-guide rows with a judgment-under-delegation lens. The IC3-to-Principal template above is configurable per role and function. Edit it once. It shows up in every review.
- Review templates with the routing-decision question. The one prompt that surfaces what the commit log can’t. Built into every cycle, not bolted on.
- Calibration rubric weighted on judgment, not volume. Calibration cohorts see compounding output and inflated output as different rows on the same screen.
- Work-surface judgment artifact capture. The two-line PR note becomes a structured feedback event, tagged to the competency it touches, searchable at calibration time. Engineering and HR subscribe to the same stream.
What This Looks Like This Week
If you are a Head of People, walk three managers this week and ask one question: how many agents are on your team. Whatever number they say, write down the gap between that and what your HRIS shows.
If you are a manager, add the routing-decision question to your next review template. Just the one sentence. Watch what gets surfaced that wasn’t there last cycle.
If you are an IC, write the two-line judgment note on every PR you ship this week. Not a form. A line. Months from now, your manager will reach for it.
None of these moves are expensive. All of them close attribution collapse before it costs you a senior IC.
If you want to see what a hybrid-team performance cycle looks like in practice, sign up for free at Branco.ai.
Related reading
- The H in HR Now Stands for Hybrid
- The Last Fast IC
- Beyond Skills: The Real Promotion Playbook
- Only Fully Automated Continuous Feedback Is Continuous Feedback
Sources and further reading
- Workday (2025), Workday Announces Agent System of Record
- Harvard Business Review (2026), To Thrive in the AI Era, Companies Need Agent Managers